L’intelligence artificielle n’est plus le domaine réservé des géants de la Silicon Valley. Que vous soyez entrepreneur, développeur ou décideur, concevoir une solution sur mesure est devenu accessible. Entre l’idée initiale et un algorithme capable de prendre des décisions pertinentes, le chemin exige une méthodologie rigoureuse. Créer une IA performante ne se résume pas à écrire du code, c’est avant tout une stratégie de données et une compréhension fine de vos besoins métier.
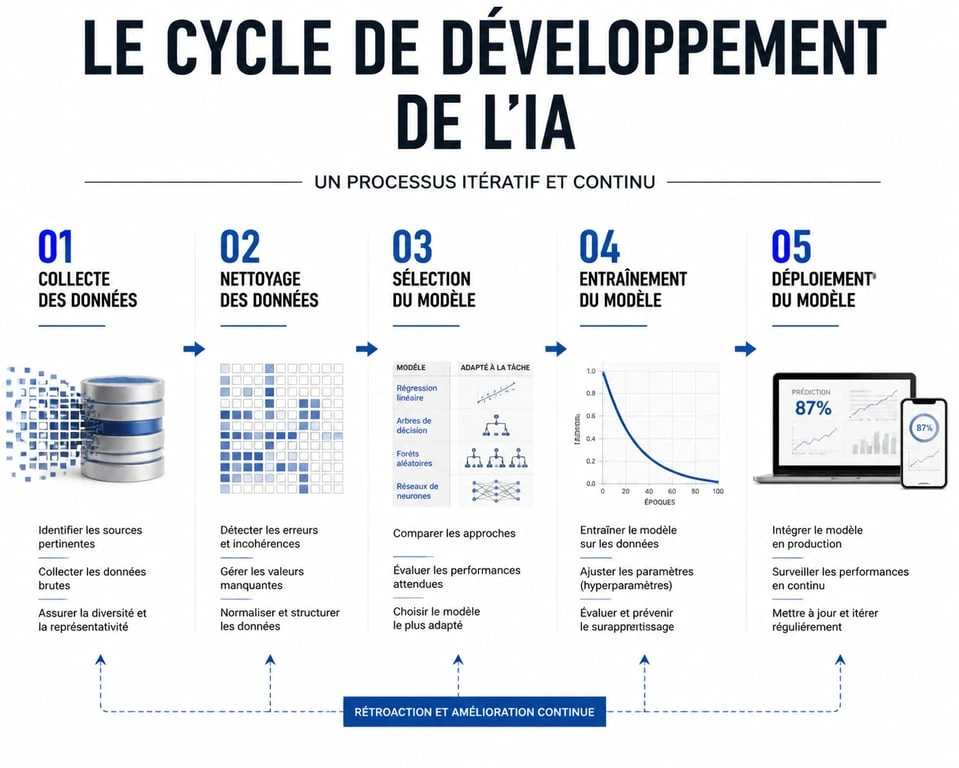
Cadrage et collecte : la fondation de votre projet
Avant de choisir un framework ou de coder en Python, définissez précisément le problème à résoudre. Une erreur classique consiste à vouloir intégrer l’IA sans objectif concret. Voulez-vous prédire le taux d’attrition de vos clients, automatiser la lecture de factures ou recommander des produits ? Chaque objectif dicte une architecture différente.
La règle des 10 000 points de données
La qualité et la quantité de vos données déterminent 80 % du succès de votre projet. Pour obtenir des résultats industriels et éviter les comportements erratiques, un minimum de 10 000 points de données (lignes, images étiquetées ou documents) est nécessaire. Sans cette masse critique, votre modèle risque l’overfitting : il apprendra vos exemples par cœur au lieu de comprendre la logique sous-jacente, devenant incapable de traiter de nouvelles situations.
Préparation et nettoyage
Les données brutes sont rarement exploitables. Elles contiennent des doublons, des valeurs manquantes ou des formats incohérents. Le data cleaning consiste à normaliser les entrées pour que l’algorithme puisse les comparer équitablement. C’est ici que vous transformez des variables textuelles en vecteurs numériques, car une intelligence artificielle calcule des probabilités sur des chiffres plutôt qu’elle ne lit du texte.
Choisir le bon modèle : du Machine Learning au Deep Learning
Une fois vos données prêtes, vous devez choisir le moteur de votre IA. Il n’existe pas de modèle universel, mais une boîte à outils adaptée à chaque usage.
L’apprentissage supervisé pour la prédiction
C’est la méthode la plus courante en entreprise. Vous fournissez à l’IA des exemples avec la réponse attendue, comme des photos de pièces défectueuses marquées « non conformes ». L’algorithme apprend à faire le lien entre les caractéristiques de l’image et l’étiquette. Cette approche est idéale pour la classification ou la régression, comme la prédiction d’un prix de vente.
Le Deep Learning et les réseaux de neurones
Pour des tâches complexes comme la reconnaissance vocale ou le traitement du langage naturel (NLP), on utilise le Deep Learning. Inspirés par la structure du cerveau humain, ces réseaux de neurones multicouches extraient eux-mêmes des caractéristiques complexes. Si vous créez un chatbot ou un outil d’analyse d’image médicale, tournez-vous vers cette technologie via des bibliothèques comme TensorFlow ou PyTorch.
| Type de modèle | Usage principal | Complexité |
|---|---|---|
| Arbres de décision | Prédiction de comportements simples | Faible |
| SVM (Support Vector Machine) | Classification de données structurées | Moyenne |
| Transformers | Génération de texte et traduction | Très élevée |
| CNN (Réseaux convolutifs) | Analyse d’images et vidéos | Élevée |
L’entraînement et le raffinement : l’art du fine-tuning
L’entraînement est la phase où l’algorithme digère vos données. Ce processus itératif demande de la puissance de calcul, souvent déportée sur des serveurs cloud équipés de GPU. Mais l’entraînement brut ne suffit pas toujours à obtenir une IA d’excellence.
Le transfert d’apprentissage pour gagner du temps
Plutôt que de partir de zéro, utilisez le transfer learning. Cette technique consiste à prendre un modèle déjà pré-entraîné sur des millions de données (comme GPT pour le texte ou ResNet pour l’image) et à l’adapter à votre cas spécifique. C’est un gain de temps qui permet d’obtenir des résultats de haute volée avec beaucoup moins de données initiales.
La flexibilité algorithmique
Il est tentant de vouloir que l’IA s’insère parfaitement dans un moule préétabli. Pourtant, la force d’une intelligence artificielle réside dans sa capacité à identifier des corrélations que l’esprit humain n’aurait pas soupçonnées. En forçant trop le modèle à respecter vos propres biais cognitifs ou des règles métier trop rigides, vous risquez de brider sa performance. Une IA efficace doit avoir la liberté statistique de trouver ses propres chemins de résolution.
Déploiement et monitoring : donner vie à l’IA
Votre modèle affiche un taux de précision satisfaisant ? L’étape suivante est le déploiement. Une IA enfermée dans un environnement de test ne sert à rien ; elle doit être intégrée à votre écosystème logiciel via une API RESTful ou un micro-service.
L’intégration dans le workflow métier
Pour que l’IA soit adoptée, elle doit être fluide. Si vous créez une IA pour aider vos commerciaux, elle doit pousser ses recommandations directement dans leur CRM. L’automatisation ne doit pas créer de nouvelles tâches, mais simplifier celles qui existent. Les outils no-code permettent aujourd’hui de créer ces ponts sans redévelopper entièrement vos interfaces.
La surveillance post-déploiement
Une IA n’est pas un produit fini. Elle est sujette à la dérive des données (data drift). Le monde change, et les données reçues en production peuvent différer de celles utilisées pour l’entraînement. Il est impératif de mettre en place un monitoring constant pour vérifier que la précision du modèle ne chute pas et prévoir des cycles de ré-entraînement réguliers.
Considérations éthiques et conformité
Créer une intelligence artificielle impose des responsabilités croissantes, notamment en Europe avec le RGPD et l’IA Act. La protection des données personnelles utilisées lors de l’entraînement est une priorité absolue. Assurez-vous que les datasets ne contiennent pas d’informations sensibles non anonymisées.
Au-delà du droit, l’explicabilité est devenue un enjeu majeur. Une IA « boîte noire » dont on ne comprend pas les décisions pose des problèmes de confiance, surtout dans la banque, l’assurance ou la santé. Développer des modèles capables de justifier leurs résultats (Explainable AI) différencie les projets amateurs des solutions professionnelles. En investissant dans la transparence de vos algorithmes, vous facilitez leur adoption et anticipez les futures régulations.
Articles qui pourraient vous intéresser :
 Auto titre : comment bien l’utiliser pour booster vos documents
Auto titre : comment bien l’utiliser pour booster vos documents
 Partage de fichier en ligne sécurisé : 3 critères techniques pour protéger vos données confidentielles
Partage de fichier en ligne sécurisé : 3 critères techniques pour protéger vos données confidentielles
 Logiciel métier sur mesure : quand le développement spécifique surpasse les progiciels standards
Logiciel métier sur mesure : quand le développement spécifique surpasse les progiciels standards
 Stratégie éditoriale SEO : 4 piliers pour transformer votre contenu en moteur de croissance
Stratégie éditoriale SEO : 4 piliers pour transformer votre contenu en moteur de croissance